Emulated FBA on SCSI
Introduction
In z/VM 5.1.0, IBM introduced native z/VM support for SCSI disks. In this chapter of our report, we illustrate the performance of z/VM-owned SCSI disks as compared to other zSeries disk choices.
Prior to z/VM 5.1.0, z/VM let a guest operating system use SCSI disks in a manner that IBM has come to describe as guest native SCSI. In this technique, the system programmer attaches a Fibre Channel Protocol (FCP) device to the guest operating system. The guest then uses QDIO operations to communicate with the FCP device and thereby transmit orders to the SCSI disk subsystem. When it is using SCSI disks in this way, the guest is wholly responsible for managing its relationship with the SCSI hardware. z/VM perceives only that the guest is conducting QDIO activity with an FCP adapter.
In z/VM 5.1.0, z/VM itself supports SCSI volumes as emulated FBA disks. These emulated FBA disks can be attached to virtual machines, can hold user minidisks, or can be given to the Control Program for system purposes (e.g., paging). In all cases, the device owner uses traditional z/VM or zSeries DASD I/O techniques, such as Start Subchannel or one of the Diagnose instructions, to perform I/O to the emulated FBA volume. The Control Program intercepts these traditional I/O calls, uses its own FCP adapter to perform the corresponding SCSI I/O, and reflects I/O completion to the device owner. This is similar to what CP does for Virtual Disk in Storage (aka VDISK).
To measure the performance of emulated FBA devices, we crafted three experiments that put these disks to work in three distinct workloads.
- We gave a Linux guest a minidisk residing on an emulated FBA volume. We put an ext2 file system on the minidisk. We ran a publicly-available disk exerciser, iozone, against the ext2 file system. We compared the performance results to those achieved for other Linux disk choices, such as guest native SCSI, dedicated ECKD, and minidisk on ECKD.
- We gave a CMS guest a minidisk residing on an emulated FBA volume. We put a CMS file system on the minidisk. We ran an XEDIT loop that read a file from the minidisk over and over again. We compared the performance results to those achieved for running the XEDIT loop against a similar CMS file system on ECKD.
- We attached an emulated FBA volume to CP as paging space. We ran a z/VM workload that induced paging. We compared the performance results to those achieved for an ECKD paging volume.
Measurement Environment
All experiments were run on the same basic test environment, which was configured as follows:
- LPAR of 2064-109, 2 GB real, 0 GB XSTORE, one engine dedicated, all other LPARs idling.
- z/VM 5.1.0 Control Program module.
- ECKD volumes were on an ESCON-attached 2105-F20.
- SCSI volumes were on an FCP-attached 2105-F20.
Linux iozone Experiment
In this experiment, we set up a Linux virtual machine on z/VM. We attached an assortment of disk volumes to the Linux virtual machine. We ran the disk exerciser iozone on each volume. We compared key performance metrics across volume types. When applicable, runs were done with minidisk caching (MDC) on and off.
The configuration was:
- 192 MB Linux guest, virtual uniprocessor, V=V.
- Linux SLES 8 SP 3, 31-bit, ext2 file systems.
- Minidisks and ext2 file systems were formatted with 4 KB blocks.
- We used iozone 3.217 with the following parameters:
- Ballast file 819200 KB.
- Record size 64 KB.
- Processor cache size set to 1024 Kbytes.
- Processor cache line size set to 256 bytes.
- File stride size set to 17 * record size.
- Throughput test with 1 process.
- Include fsync in write timing.
A "transaction" was defined as all four iozone phases combined, done over 1% of ballast file size (in other words, by definition, we did 8192 transactions in each iozone run).
For each run, we assessed performance using the following metrics:
Metric | Meaning |
IW | iozone "initial write" data rate (KB/sec). |
RW | iozone "rewrite" data rate (KB/sec). |
IR | iozone "initial read" data rate (KB/sec). |
RR | iozone "reread" data rate (KB/sec). |
CP/tx | CP processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Virt/tx | Virtual machine processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Total/tx | Total machine processor time per transaction (microseconds (usec), sum of CP/tx and virt/tx). |
Vio/tx | Virtual I/Os per transaction (obtained via CP INDICATE USER * EXP). |
CP/vio | CP processor time per virtual I/O (quotient CP/tx / Vio/tx). |
Virt/vio | Virtual machine processor time per virtual I/O (quotient Virt/tx / Vio/tx). |
Total/vio | Total machine processor time per virtual I/O (microseconds (usec), sum of CP/vio and virt/vio). |
Table 1 cites the results.
Figure 1 and Figure 2 chart key
measurements.
| Run Name | SLN9 | SFB9 | SFB0 | ECKD | EMDK | EMD0 |
| Run Type | Native SCSI | Minidisk on emulated FBA on SCSI, MDC | Minidisk on emulated FBA on SCSI, no MDC | Dedicated ECKD | Minidisk on ECKD, MDC | Minidisk on ECKD, no MDC |
| IW (KB/s) | 40038.83 | 16305.67 | 16341.82 | 9773.91 | 9688.77 | 9734.89 |
| RW (KB/s) | 40163.31 | 16299.17 | 16308.30 | 9769.19 | 9775.33 | 9758.36 |
| IR (KB/s) | 57217.09 | 17441.24 | 16159.12 | 11670.38 | 8225.54 | 11670.25 |
| RR (KB/s) | 57426.30 | 163776.33 | 16157.78 | 11670.32 | 220806.83 | 11670.66 |
| CP/tx (usec) | 345.64 | 2329.99 | 2950.21 | 289.29 | 403.23 | 289.89 |
| Virt/tx (usec) | 2797.47 | 2605.88 | 2714.83 | 2479.79 | 2492.53 | 2474.17 |
| Total/tx (usec) | 3143.11 | 4935.87 | 5665.04 | 2769.08 | 2895.76 | 2764.06 |
| Vio/tx | na | 3.56 | 3.62 | 0.87 | 0.94 | 0.86 |
| CP/vio (usec) | na | 658.24 | 818.69 | 348.27 | 438.45 | 347.84 |
| Virt/vio (usec) | na | 732.68 | 750.41 | 2866.44 | 2638.09 | 2869.66 |
| Total/vio (usec) | na | 1390.92 | 1569.1 | 3214.71 | 3076.54 | 3217.5 |
| Note: 2064-109, z/VM 5.1.0, Linux SLES 8 SP3, iozone. See text for additional configuration details. | ||||||
Figure 1. Linux iozone CPU Consumption. CP and virtual time per transaction for Linux iozone workloads. SLN9 is native Linux SCSI. SFB9 is emulated FBA, MDC. SFB0 is emulated FBA, no MDC. ECKD is dedicated ECKD. EMDK is ECKD minidisk, MDC. EMD0 is ECKD minidisk, no MDC.
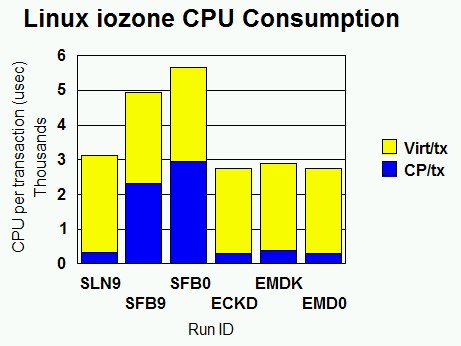 |
Figure 2. Linux iozone CPU Consumption. CP and virtual time per virtual I/O for Linux iozone workloads. SLN9 is native Linux SCSI. SFB9 is emulated FBA, MDC. SFB0 is emulated FBA, no MDC. ECKD is dedicated ECKD. EMDK is ECKD minidisk, MDC. EMD0 is ECKD minidisk, no MDC.
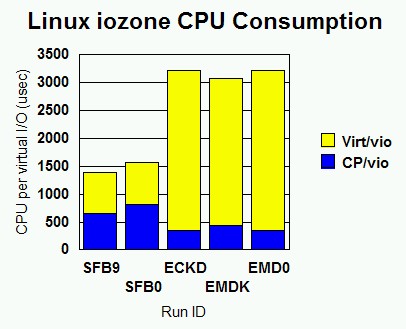 |
For the SLN9 run, the VIO metrics are marked "na" because Linux's interaction with its FCP adapter does not count as virtual I/O. (QDIO activity to the FCP adapter does not count as virtual I/O. Only Start Subchannel and diagnose I/O count as virtual I/O.)
The Linux FBA driver does about 4 times as many virtual I/Os per transaction as the Linux ECKD driver does. This suggests opportunity for improvement in the Linux FBA driver.
The ECKD runs tend to show about 8% less virtual time per transaction than the emulated FBA runs and the native SCSI runs. The Linux ECKD driver seems to be the most efficient device driver for this workload. We did not profile the Linux guest so as to investigate this further.
The MDC ON runs (SFB9 and EMDK) show interesting results as regards CP processor time. For emulated FBA, MDC ends up saving CP time per transaction. In other words, MDC is a processing shortcut compared to the normal emulated FBA path. For an ECKD minidisk, MDC uses a little extra CP time per transaction. This shows how well optimized CP is for ECKD I/O and echoes previous assessments of MDC. Note both run pairs show MDC's benefit as regards data rate on re-read.
Sanity checks: ECKD compared to EMD0 should be nearly dead-even, and it is. EMDK shows a little higher CP time per transaction than ECKD and EMD0. This makes sense given the overhead of maintaining the minidisk cache.
Comparing SLN9 to SFB0 shows the cost of the z/VM FBA emulation layer and its imported SCSI driver. When z/VM manages the SCSI disk, data rates drop off dramatically and CP time per transaction rises substantially.
Per amount of data moved, emulated FBA is expensive in terms of Control Program (CP) CPU time. We see a ratio of 9.87, comparing SFB0 to EMD0. Keep in mind that some of this expense comes from the base cost of doing a virtual I/O. Compared to EMD0, SFB0 incurs four times as much of this base cost, because Linux emits four times as many virtual I/Os to move a given amount of data. But even per virtual I/O, emulated FBA is still expensive in CP processor time. SFB0 used 2.35 times as much CP time per virtual I/O as EMD0 did.
Keep in mind that it is not really fair to use these measurements to compare ECKD data rates to SCSI data rates. The ECKD volumes we used are ESCON-attached whereas the SCSI volumes are FCP-attached. The FCP channel offers a much higher data rate (100 MB/sec) than the ESCON channel (17 MB/sec). Because the 2105-F20 is heavily cached, channel speed does make a difference in net data rate.
XEDIT Loop Experiment
In this experiment, we set up a CMS virtual machine on z/VM. We attached a minidisk to the virtual machine. The minidisk was either ECKD or emulated FBA on SCSI. We ran a Rexx exec that contained an XEDIT command inside a loop. The XEDIT command read our ballast file.
The configuration was:
- 64 MB CMS guest, virtual uniprocessor, V=V.
- CMS file system, formatted in 4 KB blocks.
- Ballast file is 5110 F-80 records (100 4 KB blocks).
A "transaction" was defined as stacking a QQUIT and then issuing the CMS XEDIT command so as to read the ballast file into memory.
We varied MDC settings across different runs so that we could see the effect of MDC on key performance metrics. Settings we used were:
- MDC OFF for the minidisk.
- MDC ON for the minidisk.
- MDC ON for the minidisk, but we issued CP SET MDC FLUSH for the minidisk immediately after each CMS XEDIT command, so as to ensure an MDC miss the next time XEDIT tried to read our file.
For each run, we assessed performance using the following metrics:
Metric | Meaning |
Tx/sec | Transactions per second |
CP/tx | CP processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Virt/tx | Virtual machine processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Total/tx | Total machine processor time per transaction (microseconds (usec), sum of CP/tx and virt/tx). |
Vio/tx | Virtual I/Os per transaction (obtained via CP monitor data). |
CP/vio | CP processor time per virtual I/O (quotient CP/tx / Vio/tx). |
Virt/vio | Virtual machine processor time per virtual I/O (quotient Virt/tx / Vio/tx). |
Total/vio | Total machine processor time per virtual I/O (microseconds (usec), sum of CP/vio and virt/vio). |
Table 2 cites the results.
Figure 3
charts key findings.
| Run Name | SCSI4KXI | 33904KX5 | SCSI4KXK | 33904KX7 | SCSI4KXJ | 33904KX6 |
| Run Type | Emulated FBA on SCSI, MDC ON. | ECKD, MDC ON. | Emulated FBA on SCSI, MDC ON, forced MDC miss. | ECKD, MDC ON, forced MDC miss. | Emulated FBA on SCSI, MDC OFF. | ECKD, MDC OFF. |
| Tx/sec | 476.82 | 474.86 | 34.75 | 428.84 | 6.38 | 27.74 |
| CP/tx (usec) | 1460.91 | 1474.56 | 6202.66 | 1663.23 | 22457.69 | 1199.68 |
| Virt/tx (usec) | 635 | 630.14 | 706.48 | 667.06 | 728.84 | 645.28 |
| Total/tx (usec) | 2095.91 | 2104.7 | 6909.14 | 2330.29 | 23186.53 | 1844.96 |
| Vio/tx | 2 | 2 | 2 | 2 | 2 | 2 |
| CP/vio (usec) | 730.455 | 737.28 | 3101.33 | 831.615 | 11228.845 | 599.84 |
| Virt/vio (usec) | 317.5 | 315.07 | 353.24 | 333.53 | 364.42 | 322.64 |
| Total/vio (usec) | 1047.955 | 1052.35 | 3454.57 | 1165.145 | 11593.265 | 922.48 |
| Note: 2064-109, z/VM 5.1.0, XEDIT reads. See text for additional configuration details. | ||||||
Figure 3. XEDIT Loop CPU Consumption. CP and virtual time per transaction for the XEDIT loops. SCSI4KXI is emulated FBA, MDC ON. 33904KX5 is ECKD MDC ON. SCSI4KXK is emulated FBA, MDC ON, forced MDC miss. 33904KX7 is ECKD MDC ON, forced MDC miss. SCSI4KXJ is emulated FBA, MDC OFF. 33904KX6 is ECKD MDC OFF.
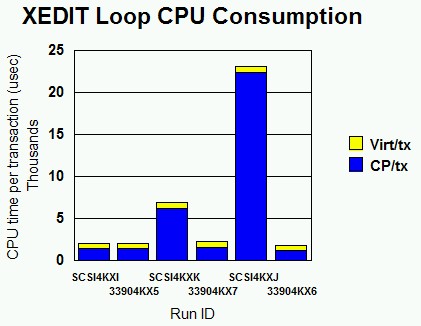 |
Runs SCSI4KXJ and 33904KX6 (MDC OFF) illustrate the raw performance difference between ECKD and emulated FBA on SCSI in this workload. Since MDC is OFF in these runs, what we are seeing is the difference in overhead between CP's driving of the SCSI LUN and its driving of an ECKD device using conventional zSeries I/O. For SCSI, the CP time per transaction is about 18.7 times that of ECKD. Transaction rate suffers accordingly, experiencing a 77% drop. Emulated FBA would be a poor choice for CMS data storage in situations where MDC offers no leverage, unless I/O rates were low.
The SCSI4KXI and 33904KX5 runs (MDC ON) illustrate the benefit of MDC for both kinds of minidisks. Transaction rates are high and about equal, which is what we would expect. Similarly, processor times per transaction are low and about equal. This experiment implies that emulated FBA might be a good choice for large minidisk volumes that are very read-intensive, such as tools disks or document libraries. Such applications would take advantage of the large volume sizes possible with emulated FBA while letting MDC cover for the long path lengths associated with the actual I/O to the 2105.
Paging Experiment
In this experiment, we set up a single CMS guest running a Rexx exec. This exec, RXTHRASH, used the Rexx storage() function to write virtual machine pages in a random fashion. We used CP LOCK to lock other virtual machines' frames into real storage, so as to leave a controlled number of real frames for pages being touched by the thrasher. In this way, we induced paging in a controlled fashion. We paged either to ECKD or to emulated FBA on SCSI.
The configuration was:
- 2048 MB CMS guest, virtual uniprocessor, V=V.
- RXTHRASH program, writing randomly over 486000 pages.
- Storage constrained via CP LOCK of other guests' pages, same CP LOCK configuration for each experiment.
- All other guests quiesced.
A "transaction" was defined as a CP paging operation. Thus, transaction rate is just the CP paging rate.
For each run, we assessed performance using the following metrics:
Metric | Meaning |
Tx/sec | Transactions per second |
CP/tx | CP processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Virt/tx | Virtual machine processor time per transaction (microseconds (usec), obtained via zSeries hardware instrumentation). |
Total/tx | Total machine processor time per transaction (microseconds (usec), sum of CP/tx and virt/tx). |
Table 3 cites the results.
Figure 4 charts key findings.
| Run Name | SCSIPG04 | 3390PG02 |
| DASD Type | Emulated FBA on SCSI | ECKD |
| Paging rate | 564 | 1376 |
| CP/tx (usec) | 217.02 | 11.55 |
| Virt/tx (usec) | 38.26 | 32.87 |
| Total/tx (usec) | 255.28 | 44.42 |
| Note: 2064-109, z/VM 5.1.0, RXTHRASH paging inducer. See text for additional configuration details. | ||
Figure 4. RXTHRASH CPU Consumption. Processor time per page fault for the RXTHRASH experiments. SCSIPG04 is emulated FBA. 3390PG02 is ECKD.
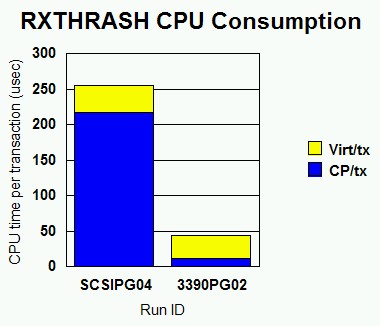 |
Like the XEDIT-with-MDC-OFF experiment, this measurement shows how expensive emulated FBA on SCSI truly is in terms of CP processor time per transaction. In this paging experiment, SCSI page faults cost 18.8 times as much in CPU as ECKD faults did. This result aligns very closely with the 18.7 ratio we saw in the XEDIT MDC OFF runs.
Because of this high processor cost, we can recommend emulated FBA as a paging volume only in situations where the z/VM system can absorb the high processor cost. If processor utilization were very low, or if paging rates were very low, emulated FBA might be a good choice for a paging volume. Note that the potential for emulated FBA volumes to be very large is not necessarily a good reason to employ them for paging. For the sake of I/O parallelism it is usually better to have several small paging volumes (3390-3s, at about 2 GB each) rather than one large one (a 3390-9 or a large emulated FBA volume). Customers contemplating SCSI-only environments will need to think carefully about processor sizings and paging volume configurations prior to running memory-constrained workloads.
Conclusions
Emulated FBA on SCSI is a good data storage choice in situations where the amount of data to be stored is large and processor time used per actual I/O is not critical. Emulated FBA minidisks can be very large, up to 1024 GB in size. This far exceeds the size of the largest ECKD volumes. High processor cost might be of no consequence to the customer if the CPU is currently lightly utilized or if the I/O rate to the emulated FBA volumes is low. Document libraries, tools disks, and data archives come to mind as possible applications of emulated FBA. If the data are read frequently, Minidisk Cache (MDC) can help reduce the processor cost of I/O by avoiding I/Os.
Customers for whom processor utilization is already an issue, or for whom high transaction rates are required, need to think carefully about using emulated FBA. z/VM Control Program (CP) processor time per I/O is much greater for emulated FBA than it is for ECKD. This gulf causes corresponding drops in achievable transaction rate.
Linux customers having large read-only ext2 file systems (tools repositories) would do well to put them on a read-only shared minidisk that resides on an emulated FBA volume. This approach lets the Linux systems share a large amount (1024 GB) of data on a single volume and lets z/VM minidisk cache guard against excessive processor consumption. Customers taking this approach will want to configure enough storage for z/VM so that its minidisk cache will be effective.
Linux customers wishing to get the very best performance from their SCSI volumes should consider assigning FCP devices to their Linux guests and letting Linux do the SCSI I/O. This configuration offers the highest data rates to the disks at processor consumption costs comparable to ECKD. Unfortunately, this configuration requires that each SCSI LUN be wholly dedicated to a single Linux guest. The 2105's LUN configuration capabilities do ease this situation somewhat.
The workloads we used to measure the performance difference between ECKD
and SCSI are specifically crafted so that they are very intensive on disk
I/O and very light on all other kinds of
work. A more precise way to say this is that per transaction, the fraction
of CPU time consumed for actually driving the disk approaches 100% of all
the CPU time used. Such a workload is
necessary so as to isolate the performance differences in these two kinds
of disk technologies. Workloads that contain significant burden in other
functional areas (for example,
networking, thread switching, or memory management) will not illustrate
disk I/O performance differences quite as vividly as workloads specifically
designed to measure only the cost of the
disk technology. In fact, workloads that do very little
disk I/O will not illustrate disk I/O performance differences much at all,
and more important, such workloads will
not benefit from changing the disk technology they use. In considering
whether to move his workload from ECKD to SCSI, the customer must
evaluate the degree to which his
workload's transaction rate (or transaction cost) is dependent on the disk
technology employed. He must then use his own judgment
about whether changing the disk
technology will result in an overall performance improvement that is
worth the migration cost.