Host Exploitation of Crypto Interruptions
Abstract
PTF UM35974 for APAR VM66534 changes how the host handles guests' requests for service from shared crypto adapters. Previously the host polled for guest requests; now the host services requests on-demand. The PTF also provides configurable support for host exploitation of real crypto interruptions. When this support is enabled, the host dequeues replies from shared crypto adapters by servicing interrupts rather than by polling.
In our workloads on-demand processing of guest requests resulted in a reduction in the amount of time it took the host to start processing a guest request. NSERV, a measurement of how long it takes the host to start processing a guest request, experienced a reduction in the range of 80.0% to 95.3%. The exploitation of crypto interruptions, when enabled, resulted in a reduction in the amount of time it took the host to start dequeuing a reply from a crypto adapter. RSERV, a measurement that includes the time it takes the host to initiate the dequeuing of a reply from a crypto adapter, experienced a reduction of 42.1% to 61.1%. The effect these reductions have on ETR is dependent on many factors and ranged from no change to a 274.2% improvement. Customer results are expected to vary likewise based on system configuration and workload.
Introduction
This section of the performance report presents key measurements demonstrating the effect the PTF has on the service time of APVIRT shared pool crypto operations, CP CPU utilization, and external throughput. APVIRT shared pool adapters are those defined to CP by the CRYPTO APVIRTUAL statement in the system configuration file or the ATTACH CRYPTO TO SYSTEM command.
The host, CP, uses two persistent tasks to process APVIRT work. The host enqueue-task (NQ-task) takes guest APVIRT requests and forwards them to real crypto adapters in the APVIRT shared pool. The host dequeue task (DQ-task) looks for replies from APVIRT shared pool adapters, dequeues them, and forwards the replies to the guests.
Prior to the PTF both tasks employed a polling loop to look for work periodically. Depending on the frequency of crypto requests the wait time of the polling loops varied between 50 µs and 200 ms. The principle aim of the new function is to reduce the latency inherent with polling by:
- Enabling the on-demand initiation of CP's NQ-task to process APVIRT requests from guests immediately.
- Exploiting crypto interrupts to initiate CP's DQ-task to process replies from APVIRT shared crypto adapters immediately.
Note: The NQ-task enhancements are always active; however, the DQ-task enhancements can be enabled or disabled via the CP SET CRYPTO POLLING command. By default, they are disabled.
The PTF introduces new fields to monitor record D5 R9 MRPRCAPC - Crypto Performance Counters. Three of the new fields, along with two existing fields, provide insight into the service time associated with processing APVIRT shared pool crypto operations. Each field contains an accumulation of time in microseconds and measures the time spent in a specific phase of processing an APVIRT crypto operation.
- PRCAPC_CRYVSERV (VSERV) is an existing field that accumulates time from the point the guest delivers a complete request to CP to the point the guest starts to receive the reply.
- PRCAPC_CRYHSERV (HSERV) is a new field that accumulates time from the point the guest delivers a complete request to CP to the point where CP receives a complete reply from the crypto adapter. HSERV is a subinterval of VSERV.
- PRCAPC_CRYNSERV (NSERV) is a new field that accumulates time from the point the guest delivers a complete request to CP to the point CP delivers the complete request to the crypto adapter. NSERV is a subinterval of HSERV.
- PRCAPC_CRYRSERV (RSERV) is an existing field that accumulates time from the point CP delivers a complete request to the crypto adapter to the point where CP receives a complete reply from the crypto adapter. RSERV is a subinterval of HSERV. RSERV plus NSERV is approximately equal to HSERV.
- PRCAPC_CRYDSERV (DSERV) is a new field that accumulates time from the point CP receives a complete reply from the crypto adapter to the point where the guest starts to receive the reply. DSERV is a subinterval of VSERV.
Figure 1 illustrates the conceptual relationships among the D5 R9 service time accumulators.
| Figure 1. Conceptual relationships among VSERV, HSERV, NSERV, RSERV, and DSERV. |
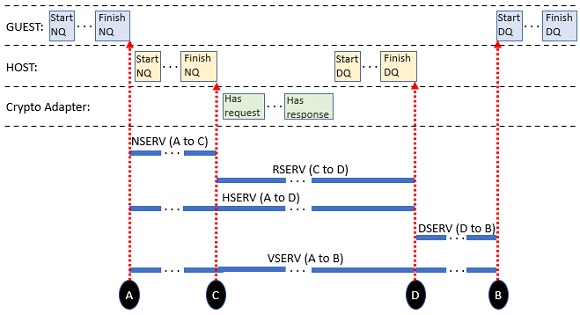
|
| Notes: The boxes in this diagram are not drawn to scale. |
The on-demand initiation of CP's NQ-task is expected to yield a reduction in NSERV. When enabled, the exploitation of crypto interruptions is expected to yield a reduction in RSERV.
The new function does not extend to the guest exploitation of crypto interruptions. The guest continues to use a polling mechanism to receive replies from the host. DSERV is dependent on the guest's ability to run and its polling logic. By default, the Linux polling interval is 250 µs, but it can be modified by the chzcrypt --poll-timeout command.
Method
All experiments were run on an IBM z15 model 8561-T01 processor and used a logical partition configured with 128 GB central storage and eight dedicated IFL cores. While the measurements were taken, no other partitions were activated, and no other workloads were running. All experiments were performed without SMT and then repeated with SMT-2. Some experiments are not discussed in this report.
Experiments used Linux guests running SLES 12 SP 5. Each guest employed a single user to invoke the OpenSSL speed utility continuously to drive RSA 1024 sign and verify operations. Each guest made use of the APVIRT shared crypto pool. The APVIRT shared pool was defined with two cryptographic domains, each on a separate Crypto Express7 adapter configured in accelerator mode (i.e., AP type CEX7A). The RSA 1024 sign and verify operations generated a single enqueue and dequeue per operation.
Three sets of measurements were collected for each experiment: a baseline measurement, a polling measurement using SET CRYPTO POLLING ON, and an interrupt measurement using SET CRYPTO POLLING OFF. The baseline runs used a pre-PTF development CP module enhanced to produce monitor records containing PRCAPC_CRYHSERV, PRCAPC_CRYNSERV, and PRCAPC_CRYDSERV in monitor record D5 R9. The polling and interrupt runs used a CP module containing the PTF.
The key metrics focused on in this report are: NSERV per virtual crypto request enqueued (NSERV per VNQ), RSERV per virtual crypto operation enqueued (RSERV per VNQ), total CP busy per 1000 crypto operations enqueued (CP busy per 1000 VNQs), and external throughput rate (ETR). The measurements from the polling and interrupt runs are compared back to the baseline measurements. Other metrics are discussed as appropriate.
Results and Discussion
In the tables below, NSERV, RSERV, HSERV, DSERV, and VSERV per VNQ are in microseconds. Total, guest, and CP busy per 1000 VNQs are expressed as a percentage of total available CPU. ETR (external throughput rate) represents the number of virtual enqueues per elapsed second. This provides an approximation of the number of crypto operations performed per second.
Table 1 presents the results from a workload without SMT, running ten Linux guests, each guest using the Linux default poll-time of 250 µs, and employing a single Linux user to execute the OpenSSL speed utility with ten threads.
| Table 1. 10 Guests, 10 Threads, non-SMT, Default Linux poll-time | |||||
| Run ID | DBDN | DPDN | DIDN | DPDN Delta | DIDN Delta |
| method | baseline | polling | interrupts | ||
| NSERV per VNQ | 72.643 | 4.713 | 14.520 | -93.5% | -80.0% |
| RSERV per VNQ | 116.751 | 112.622 | 45.552 | -3.5% | -61.0% |
| HSERV per VNQ | 189.394 | 117.293 | 60.078 | -38.1% | -68.3% |
| DSERV per VNQ | 1296.170 | 1256.676 | 317.990 | -3.0% | -75.5% |
| VSERV per VNQ | 1485.551 | 1373.969 | 378.067 | -7.5% | -74.6% |
| total busy per 1000 VNQs | 1.1478 | 1.3071 | 1.5029 | 13.9% | 30.9% |
| guest busy per 1000 VNQs | 0.5178 | 0.5352 | 0.5641 | 3.4% | 8.9% |
| CP busy per 1000 VNQs | 0.6299 | 0.7719 | 0.9388 | 22.5% | 49.0% |
| ETR | 46717.08 | 50319.05 | 172346.20 | 7.7% | 268.9% |
Notes:
| |||||
Table 2 presents the results from a workload with SMT-2, running ten Linux guests, each guest using the Linux default poll-time of 250 µs, and employing a single Linux user to execute the OpenSSL speed utility with ten threads. The only difference between this workload and the workload from the Table 1 is this workload used SMT-2.
| Table 2. 10 Guests, 1 Thread, SMT-2, Default Linux poll-time | |||||
| Run ID | DBD2 | DPD2 | DID2 | DPD2 Delta | DID2 Delta |
| method | baseline | polling | interrupts | ||
| NSERV per VNQ | 87.734 | 3.626 | 17.073 | -95.9% | -80.5% |
| RSERV per VNQ | 118.234 | 111.302 | 46.006 | -5.9% | -61.1% |
| HSERV per VNQ | 205.968 | 114.853 | 63.074 | -44.2% | -69.4% |
| DSERV per VNQ | 1279.835 | 1242.840 | 303.880 | -2.9% | -76.3% |
| VSERV per VNQ | 1485.803 | 1357.692 | 366.953 | -8.6% | -75.3% |
| total busy per 1000 VNQs | 1.1781 | 1.3327 | 1.6712 | 13.1% | 41.9% |
| guest busy per 1000 VNQs | 0.5220 | 0.5331 | 0.5833 | 2.1% | 11.7% |
| CP busy per 1000 VNQs | 0.6560 | 0.7995 | 1.0880 | 21.9% | 65.9% |
| ETR | 46704.28 | 50910.57 | 174790.20 | 9.0% | 274.2% |
Notes:
| |||||
NSERV per virtual enqueue decreased 93.5% and 95.9% for the polling runs. NSERV per virtual enqueue decreased 80.0% and 80.5% for the interrupt runs. A decrease in NSERV per virtual enqueue was expected for both sets of runs due to the on-demand initiation of the NQ-task.
RSERV per virtual enqueue decreased 3.5% and 5.9% for the polling runs. This decrease might be attributed to overall changes in the DQ-task path. RSERV per virtual enqueue decreased 61.0% and 61.1% for the interrupt runs. A decrease of this magnitude was expected when using interrupts to drive the DQ-task.
CP busy per 1000 VNQs increased 22.5% and 21.9% for the polling runs while the number of virtual enqueues per second, ETR, increased 7.7% and 9.7%. CP busy per 1000 VNQs for the interrupt runs increased 49.0% and 65.9% while the number of virtual enqueues per second, ETR, increased 268.9% and 272.2%. The increase in the CP busy time might seem alarming, but a very small number increasing by 65.9% is still a very small number. When SMT was not used, the raw increase in CP busy per 1000 VQNs was 0.142 and when SMT-2 was used it was 0.1435. The increase in the CP busy time is a reasonable trade-off given the increase in ETR.
Focusing on NSERV and RSERV highlights the efficiencies introduced with the PTF, but many factors influence how these efficiencies affect the overall throughput of a workload. To illustrate this the workload was changed slightly. Table 3 presents the results of re-running the Table 1 workload, but executing the OpenSSL speed utility using a single thread rather than ten.
| Table 3. 10 Guests, 1 Thread, non-SMT, Default Linux poll-time | |||||
| Run ID | CBDN | CPDN | CIDN | CPDN Delta | CIDN Delta |
| method | baseline | polling | interrupts | ||
| NSERV per VNQ | 53.954 | 2.546 | 2.291 | -95.3% | -95.8% |
| RSERV per VNQ | 123.162 | 121.836 | 71.348 | -1.1% | -42.1% |
| HSERV per VNQ | 177.115 | 124.497 | 73.755 | -29.7% | -58.4% |
| DSERV per VNQ | 1316.767 | 1369.687 | 1420.626 | 4.0% | 7.9% |
| VSERV per VNQ | 1493.897 | 1494.210 | 1494.416 | 0.0% | 0.0% |
| total busy per 1000 VNQs | 2.0722 | 1.8162 | 1.7502 | -12.4% | -15.5% |
| guest busy per 1000 VNQs | 0.8668 | 0.8169 | 0.7982 | -5.8% | -7.9% |
| CP busy per 1000 VNQs | 1.2054 | 0.9993 | 0.9520 | -17.1% | -21.0% |
| ETR | 6666.17 | 6666.17 | 6666.17 | 0.0% | 0.0% |
Notes:
| |||||
Threads used by the OpenSSL speed utility issue a crypto operation and wait for a reply before issuing their next crypto operation. In the single-threaded case a Linux guest will find at most one reply to dequeue when it polls; however, in the multi-threaded case a Linux guest might find multiple replies to dequeue when it polls.
DSERV is a function of Linux poll-time plus processing time in the guest to initiate a virtual dequeue. When the OpenSSL speed utility is used with a single thread, DSERV becomes a gating factor. Fortunately, most applications are multi-threaded and should not encounter this behavior.
HSERV per virtual enqueue (i.e., the sum of NSERV and RSERV) decreased 29.7% in the polling run and 58.4% in the interrupt run. ETR, however, remained constant across all three runs because the decrease in HSERV was negated by increases in DSERV, thus causing VSERV to remain constant.
To further illustrate how external factors influence the overall throughput of a workload, the workload was tweaked once again. Table 4 presents the results of re-running the Table 3 workload using a with a Linux poll-time of 50 µs.
| Table 4. 10 Guests, 1 Threads, non-SMT, 50 µs Linux poll-time | |||||
| Run ID | CB5N | CP5N | CI5N | CP5N Delta | CI5N Delta |
| method | baseline | polling | interrupts | ||
| NSERV per VNQ | 40.509 | 3.143 | 3.260 | -92.2% | -92.0% |
| RSERV per VNQ | 101.248 | 89.586 | 51.648 | -11.5% | -49.0% |
| HSERV per VNQ | 141.757 | 92.690 | 54.907 | -34.6% | -61.3% |
| DSERV per VNQ | 24.288 | 24.099 | 14.336 | -0.8% | -41.0% |
| VSERV per VNQ | 166.054 | 116.791 | 69.246 | -29.7% | -58.3% |
| total busy per 1000 VNQs | 2.3867 | 2.0775 | 1.9485 | -13.0% | -18.4% |
| guest busy per 1000 VNQs | 1.0723 | 0.9286 | 0.8467 | -13.4% | -21.0% |
| CP busy per 1000 VNQs | 1.3144 | 1.1489 | 1.1018 | -12.6% | -16.2% |
| ETR | 58266.01 | 81673.42 | 132577.60 | 40.2% | 127.5% |
Notes:
| |||||
A Linux poll-time of 50 µs was selected to allow the guest to dequeue replies in a more timely manner, thus reducing both DSERV and VSERV. Reducing VSERV means our single OpenSSL thread will receive a reply and start the next crypto operation quicker, as demonstrated by the significantly higher ETR in runs CB5N, CP5N, and CI5N versus run CBDN, CPDN, and CPDN.
This report makes no recommendation on how to set Linux poll-time. The poll-time value used in the Table 4 runs was selected to demonstrate the effect reducing DSERV has on the ETR of a single threaded workload issuing crypto operations in a tight loop. Reducing DSERV comes with a price. More frequent polling means more overhead. For example, runs CBDN, CPDN, and CIDN using the default Linux poll-time experienced approximately 200,000 unsuccessful dequeue requests per monitor interval, whereas runs CB5N, CB5N, and CI5N using a 50 µs Linux poll-time experienced approximately 6,000,000 unsuccessful dequeue requests per monitor interval.
Summary
The principle aim of the PTF is to reduce the latency inherent with polling logic used by CP to initiate the host's NQ-task and DQ-task. With the PTF:
- The host's NQ-task is driven via an on-demand initiation.
- By default, a polling technique is used to drive the host's DQ-task.
- A new SET CRYPTO POLLING OFF command is available to drive the DQ-task based on interrupts generated by the shared crypto adapters.
NSERV per virtual enqueue is a metric that includes the time it takes the host to initiate the NQ-task once a guest completes enqueuing a virtual request. The workloads used to generate the tables in this report experienced a reduction in NSERV of 80% to 95.9%. Additional workloads in our lab saw an NSERV reduction in the range of 42.7% to 99.2%.
RSERV per virtual enqueue is a metric that includes the time it takes the host to initiate the DQ-task once the crypto adapter completes a reply. The workloads used to generate the tables in this report experienced a reduction in RSERV of 42.1% to 61.1% when the DQ-task was initiated by crypto adapter interrupts. Additional workloads in our lab saw an RSERV reduction in the range of 22.7% to 89.5% when the DQ-task was initiated by crypto adapter interrupts.
The impact NSERV and RSERV have on ETR is dependent on many factors. The workloads used to generate the tables in this report experienced no change in ETR up to a 274.2% increase. Additional workloads in our lab saw similar behavior.
Our workloads ran in a very controlled environment and used a
tight loop to generate a continuous stream of cryptographic
operations. Customer workloads might experience different results.