System Scaling Improvements
Abstract
On z13, z/VM for z13 is supported in an LPAR consisting of up to 64 logical CPUs. To validate scaling IBM used one WAS-based workload, two Apache-based workloads, and selected microbenchmarks that validated scaling improvements carried out against three known problem areas. The WAS-based workload showed correct scaling up to 64 logical CPUs, whether running in non-SMT mode or in SMT-2 mode. The Apache-based workloads showed correct scaling up to 64 logical CPUs provided 32 or fewer cores were in use, but in runs beyond 32 cores there was some rolloff. The microbenchmarks showed acceptable levels of constraint relief.
Introduction
In z/VM for z13 and the PTF for APAR VM65696 IBM made improvements in the ability of z/VM to run in LPARs containing multiple logical CPUs.
This chapter describes the workloads IBM used to evaluate the new support and the results obtained in the evaluation.
Background
In z/VM for z13 and the PTF for APAR VM65696 IBM made improvements in the ability of z/VM to run in LPARs containing multiple logical CPUs. Improvements were made in all of the following areas:
- Use of the scheduler lock.
The situations in which the
scheduler lock had to be held exclusive were decreased.
This
decreased opportunity for scheduler lock contention and
increased opportunity for parallelism
in accessing scheduler data structures
such as the dispatch list.
In APAR VM65696
the scheduler lock was moved
to its own cache lines.
- Use of the NDMBK lock.
The NDMBK is a control block used
to hold data moving through a guest LAN or VSWITCH.
A set of free, preallocated NDMBKs is kept on hand
so as to reduce calls to the z/VM Control Program's
free storage manager. The data structure used to hold
this set of preallocated NDMBKs was changed
to decrease opportunity for lock contention.
- Guest PTE serialization.
For a certain Linux memory thrashing
workload used in IBM z/VM Performance,
Endicott, it was observed that several of the guest
virtual CPUs were all attempting to issue ISKE against
the same guest page at the same time.
Because guest ISKE is simulated, this in turn caused
z/VM on several logical CPUs to try concurrently
to acquire a lock on the guest PTE.
The technique
used for locking a guest PTE was changed
to decrease opportunity for lock contention.
- VDISK locking.
When it handles a guest's request to do I/O
to a VDISK, z/VM must translate the guest's channel program and
then move data between the guest's storage and the address space
holding the VDISK's data.
The code that processes the guest's channel program was changed
to increase efficiency of CCW translation and
to decrease opportunity for lock contention.
- Real storage management improvements. z/VM's real storage manager maintains per-logical-CPU short lists of free, cleared 4 KB frames that the CPC millicode or the z/VM Control Program can use to resolve first-time page faults. The logic that keeps these lists filled was improved to replenish them in a more timely, demand-sensitive way, thus decreasing their likelihood of going empty and thereby increasing the opportunity for parallelism in fault resolution. Also, RSA2GLCK was moved so it is now alone in its own cache line.
To evaluate these changes IBM used several different workloads. In most cases the workloads were chosen for their ability to put stress onto specifically chosen areas of the z/VM Control Program. One other workload, a popular benchmark called DayTrader, was used for contrast.
Method
To evaluate the scaling characteristics of z/VM for z13, six workloads were used. This section describes the workloads and configurations.
A typical run lasted ten minutes once steady-state was reached. Workload driver logs were collected and from those logs ETR was calculated. MONWRITE data, including CPU MF host counters, was always collected. Lab-mode sampler data was collected if the experiment required it.
Unless otherwise specified, all runs were done in a dedicated Linux-only mode LPAR with only one LPAR activated on the CPC.
DayTrader
The DayTrader suite is a popular benchmark used to evaluate performance of WAS-DB/2 deployments. A general description can be found in our workload appendix.
The purpose of running DayTrader for this evaluation was to check scaling of z/VM for z13 using a workload customers might recognize and which is not necessarily crafted to stress specific areas of the z/VM Control Program. In this way we hope our runs of DayTrader might offer customers more guidance than do the results obtained from the targeted workloads we often run for z/VM Control Program performance evaluations.
In this workload all Linux guests were Red Hat 6.0. Our AWM client machine was a virtual 4-way with 1024 MB of guest storage. Our WAS-DB/2 server machines were virtual 2-ways with 1024 MB of guest storage. To scale up the workload we added WAS-DB/2 servers and configured the client to drive all servers. Table 1 gives the counts used.
| Table 1. DayTrader configurations. | |||||||
| Cores | 3 | 8 | 16 | 24 | 32 | 48 | 64 |
| AWM clients | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| WAS-DB/2 servers | 4 | 12 | 22 | 36 | 46 | 72 | 90 |
| Notes: None. | |||||||
These runs were all done on a z13, 2964-NC9, storage-rich.
For each number of cores, runs were done in non-SMT and SMT-2 configurations, except that for LPARs exceeding 32 cores, SMT-2 runs were not done. This is because the support limit for z/VM for z13 is 64 logical CPUs.
All runs were done with a z/VM 6.3 internal driver built on November 13, 2014. This driver contained the z13 exploitation PTF.
For this workload ETR is defined to be the system's aggregate DayTrader transaction rate, scaled by a constant.
Apache CPU Scalability
Apache CPU Scalability consists of Linux client guests running Application Workload Modeler (AWM) communicating with Linux server guests running the Apache web server. All Linux guests were SLES 11 SP 1. The client guests are all virtual 1-ways with 1 GB of guest real. The server guests are all virtual 4-ways with 10 GB of guest real. The ballast URIs are chosen so that the HTTP serving is done out of the Linux server guests' file caches. The workload is run storage-rich, has no think time, and is meant to run the LPAR completely busy.
Apache CPU Scalability is used to look for problems in the z/VM scheduler or dispatcher, such as problems with the scheduler lock. Because it uses virtual networking to connect the clients and the servers, it will also find problems in that area.
Table 2 shows the configurations used.
| Table 2. Apache CPU Scalability Configurations | |||||
| Cores | 4 | 8 | 16 | 32 | 64 |
| Central storage, MB | 65536 | 131072 | 262144 | 524288 | 1048576 |
| AWM clients | 3 | 6 | 12 | 24 | 48 |
| AWM servers | 8 | 16 | 32 | 64 | 128 |
| Notes: None. | |||||
These runs were all done on a z13, 2964-NC9.
For each number of cores, runs were done in non-SMT and SMT-2 configurations, except that for LPARs exceeding 32 cores, SMT-2 runs were not done. This is because the support limit for z/VM for z13 is 64 logical CPUs.
Base runs were done using z/VM 6.3 plus all closed service, built on January 30, 2015. This build contained the z13 compatibility SPE PTF from APAR VM65577.
Comparison runs were done using a z/VM 6.3 internal driver built on March 4, 2015. This build contained the z/VM z13 exploitation PTF from APAR VM65586 and the PTF from APAR VM65696.
For this workload ETR is defined to be the system's aggregate HTTP transaction rate, scaled by a constant.
Apache DASD Paging
Apache DASD Paging consists of Linux client guests running Application Workload Modeler (AWM) communicating with Linux server guests running the Apache web server. All Linux guests were SLES 11 SP 1. The client guests are all virtual 1-ways with 1 GB of guest real. The server guests are all virtual 4-ways with 10 GB of guest real. The ballast URIs are chosen so that the HTTP serving is done out of the Linux server guests' file caches. There is always 16 GB of central, and there are always 24 Linux client guests, and there are always 32 Linux server guests. The workload has no think time delay, but owing to paging delays the LPAR does not run completely busy.
Apache DASD Paging is meant for finding problems in z/VM storage management. The virtual-to-real storage ratio is about 21:1. The instantiated-to-real storage ratio is about 2:1. Because of its level of paging, T/V is somewhat higher than we would usually see in customer MONWRITE data.
These runs were all done on a z13, 2964-NC9.
For each number of cores, runs were done in non-SMT and SMT-2 configurations, except that for LPARs exceeding 32 cores, SMT-2 runs were not done. This is because the support limit for z/VM for z13 is 64 logical CPUs.
Base runs were done using z/VM 6.3 plus all closed service, built on January 30, 2015. This build contained the z13 compatibility SPE PTF from APAR VM65577.
Comparison runs were done using a z/VM 6.3 internal driver built on March 4, 2015. This build contained the z/VM z13 exploitation PTF from APAR VM65586 and the PTF from APAR VM65696.
For this workload ETR is defined to be the system's aggregate HTTP transaction rate, scaled by a constant.
Microbenchmark: Guest PTE Serialization
The z/VM LPAR was configured with 39 logical processors and was storage-rich. One Linux guest, SLES 11 SP 3, was defined with 39 virtual CPUs and enough virtual storage so Linux would not swap. The workload inside the Linux guest consisted of 39 instances of the Linux application memtst. This application is a Linux memory allocation workload that drives a high demand for the translation of guest pages.
All runs were done on a zEC12, 2827-795.
The base case was done with z/VM 6.3 plus all closed service as of August 6, 2013.
The comparison case was done on an IBM internal z/VM 6.3 driver built on February 20, 2014 with the PTE serialization fix applied. This fix is included in the z13 exploitation SPE.
ETR is not collected for this workload. The only metric of interest is CPU utilization incurred spinning while trying to lock PTEs.
Microbenchmark: VDISK Serialization
The VDISK workload consists of 10n virtual uniprocessor CMS users, where n represents the number of logical CPUs in the LPAR. Each user has one 512 MB VDISK defined for it. Each user runs the CMS DASD I/O generator application IO3390 against its VDISK, paced to run at 1233 I/Os per second, with 100% of the I/Os being reads.
The per-user I/O pace was chosen as follows. IBM searched its library of customer-supplied MONWRITE data for the customer system that had the highest aggregate virtual I/O rate we had record of ever having seen. From this we calculated said system's I/O rate per logical CPU in its LPAR. We then assumed ten virtual uniprocessor guests per logical CPU as a sufficiently representative ratio for customer environments. By arithmetic we calculated each user in our experiment ought to run at 1233 virtual I/Os per second.
All runs were done on a zEC12, 2827-795.
The base runs were done on z/VM 6.3 plus all closed service as of August 6, 2013.
The comparison runs were done on an IBM internal z/VM 6.3 driver built on January 31, 2014 with the VDISK serialization fix applied. This fix is included in the z13 exploitation SPE.
For this workload ETR was defined to be the system's aggregate virtual I/O rate to its VDISKs, scaled by a constant.
Microbenchmark: Real Storage Management Improvements
The real storage management improvements were evaluated using a VIRSTOR workload configured to stride through guest storage at a high rate. The workload is run in a storage-rich LPAR so that eventually all guest pages used in the workload are instantiated and resident. At that point pressure on z/VM real storage management has concluded.
One version of this workload was run in a 30-way LPAR. This version used two different kinds of guests, each one touching some fraction of its storage in a loop. The first group consisted of twenty virtual 1-way guests, each one touching 9854 pages (38.5 MB) of its storage. The second group consisted of 120 virtual 1-way guests, each one touching 216073 pages (844 MB) of its storage.
Another version of this workload was run in a 60-way LPAR. This version of the workload used the same two kinds of guests as the previous version, but the number of guests in each group was doubled.
Two metrics are interesting in this workload. One metric is the engines spent spinning on real storage management locks as a function of time. The other is the amount of time needed for the workload to complete its startup transient.
All runs were done on a zEC12, 2827-795.
The base case was done with z/VM 6.3 plus all closed service as of August 6, 2013.
The comparison case was done on an IBM internal z/VM 6.3 driver built on May 7, 2014 with the real storage management improvements fix applied. This fix is included in the z13 exploitation SPE.
The z/VM Monitor was set for a sample interval of six seconds.
Results and Discussion
Expectation
For the WAS-based and Apache-based workloads, scaling expectation is expressed by relating the workload's ITR to what the z13 Capacity Adjustment Factor (CAF) coefficients predict. The CAF coefficient for an N-core LPAR tells how much computing power each of those N cores is estimated to be worth compared to the computing power available in a 1-core LPAR. For example, for z13 the MP CAF coefficient for N=4 is 0.890 which means that a 4-core LPAR is estimated to be able to deliver (4 x 0.890) = 3.56 core-equivalents of computing power. IBM assigns CAF coefficients to a machine based on how well the machine ran a laboratory reference workload at various N-core configurations. A machine's CAF coefficients appear in the output of the machine's Store System Information (STSI) instruction.
Figure 1 shows a graph that illustrates the ideal, linear, slope-1 scaling curve and the scaling curve predicted by the z13 CAF coefficients.
| Figure 1. Hypothetical z13 scaling curves. |
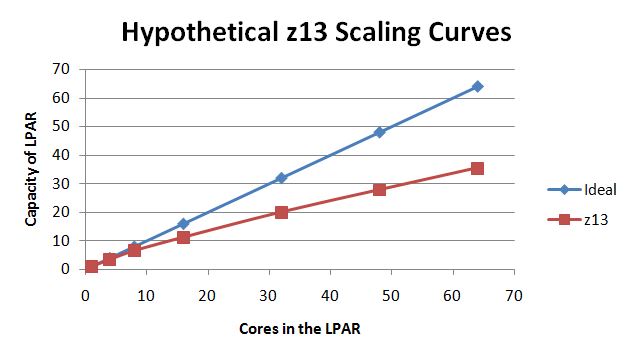
|
Expectation based on CAF scaling applies only to ITR values. ETR of a workload can be limited by many factors, such as DASD speed, network speed, available parallelism, or the speed of a single instruction stream.
For the microbenchmark workloads, our expectation is that the improvement would substantially or completely eliminate the discovered z/VM Control Program serialization problem.
DayTrader
Table 3 illustrates basic results obtained in the non-SMT DayTrader scaling suite.
| Table 3. DayTrader Results, non-SMT | |||||||
| Cores | 3 | 8 | 16 | 24 | 32 | 48 | 64 |
| Run ID | DTDBR03 | DTDBR06 | DTDBR0F | DTDBR07 | DTDBR04 | DTDBR08 | DTDBR05 |
| ETR | 278 | 652 | 1250 | 1833 | 2478 | 3566 | 4555 |
| ITR | 283 | 677 | 1315 | 1878 | 2579 | 3728 | 4791 |
| Avg logical PU %busy | 98.2 | 96.5 | 95.1 | 97.6 | 96.1 | 95.7 | 95.1 |
| T/V ratio | 1.01 | 1.01 | 1.01 | 1.02 | 1.02 | 1.04 | 1.09 |
| Notes: 2964-NC9; z/VM for z13. | |||||||
Table 4 illustrates basic results obtained in the SMT-2 DayTrader scaling suite.
| Table 4. DayTrader Results, SMT-2 | |||||
| Cores | 3 | 8 | 16 | 24 | 32 |
| Run ID | DTDBR09 | DTDBR0B | DTDBR0E | DTDBR0C | DTDBR0A |
| ETR | 351 | 847 | 1526 | 2200 | 2972 |
| ITR | 354 | 890 | 1663 | 2389 | 3236 |
| Avg logical PU %busy | 99 | 95 | 92 | 92 | 92 |
| T/V ratio | 1.01 | 1.01 | 1.02 | 1.02 | 1.03 |
| Notes: 2964-NC9; z/VM for z13. | |||||
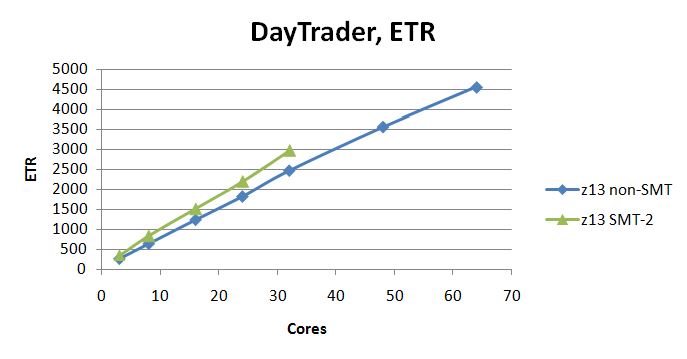
Figure 2 illustrates the ETR achieved in the DayTrader scaling suite.
| Figure 2. DayTrader ETR scaling curves. 2964-NC9, dedicated LPAR, storage-rich. z/VM 6.3 with z13 exploitation SPE, non-SMT. z/VM 6.3 with z13 exploitation SPE, SMT-2. |
|
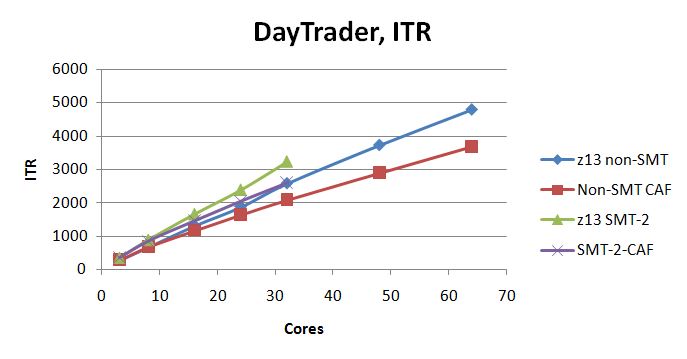
Figure 3 illustrates the ITR achieved in the DayTrader scaling suite. The curves marked CAF are the expectation curves formed by computing how the experiment's smallest run would have scaled up according to the CAF coefficients.
| Figure 3. DayTrader ITR scaling curves. 2964-NC9, dedicated LPAR, storage-rich. z/VM 6.3 with z13 exploitation SPE, non-SMT. z/VM 6.3 with z13 exploitation SPE, SMT-2. |
|
DayTrader scaled correctly up to 64 logical CPUs, whether non-SMT or SMT-2.
Apache CPU Scalability
Table 5 illustrates basic results from the Apache CPU Scalability suite, using z/VM 6.3 with only the z13 compatibility SPE.
| Table 5. Apache CPU Scalability Results, Compatibility | |||||
| Cores | 4 | 8 | 16 | 32 | 64 |
| Run ID | A04XPUX0 | A08XPUX0 | A16XPUX0 | A32XPUX0 | A64XPUX0 |
| ETR | 6849 | 11855 | 22234 | 16789 | na |
| ITR | 7335 | 12694 | 23568 | 17855 | na |
| Avg logical PU %busy | 93 | 93 | 94 | 95 | na |
| T/V ratio | 1.13 | 1.14 | 1.18 | 3.84 | na |
| Notes: 2964-NC9; z/VM 6.3 with VM65577. | |||||
Table 6 illustrates basic results from the Apache CPU Scalability suite, using z/VM for z13, non-SMT.
| Table 6. Apache CPU Scalability Results, non-SMT | |||||
| Cores | 4 | 8 | 16 | 32 | 64 |
| Run ID | A04XX0T0 | A08XX0T0 | A16XX0T0 | A32XX0T0 | A64XX0T0 |
| ETR | 6690 | 11714 | 22621 | 42123 | 37248 |
| ITR | 6878 | 12183 | 23158 | 43478 | 39698 |
| Avg logical PU %busy | 97 | 96 | 98 | 97 | 94 |
| T/V ratio | 1.13 | 1.13 | 1.15 | 1.27 | 2.97 |
| Notes: 2964-NC9; z/VM for z13 with VM65696. | |||||
Table 7 illustrates basic results from the Apache CPU Scalability suite, using z/VM for z13, SMT-2.
| Table 7. Apache CPU Scalability Results, SMT-2 | ||||
| Cores | 4 | 8 | 16 | 32 |
| Run ID | A04XX0T1 | A08XX0T1 | A16XX0T1 | A32XX0T1 |
| ETR | 5206 | 10048 | 19679 | 35048 |
| ITR | 10557 | 20374 | 40642 | 64320 |
| Avg logical PU %busy | 49 | 49 | 48 | 55 |
| T/V ratio | 1.13 | 1.16 | 1.19 | 1.42 |
| Notes: 2964-NC9; z/VM for z13 with VM65696. | ||||
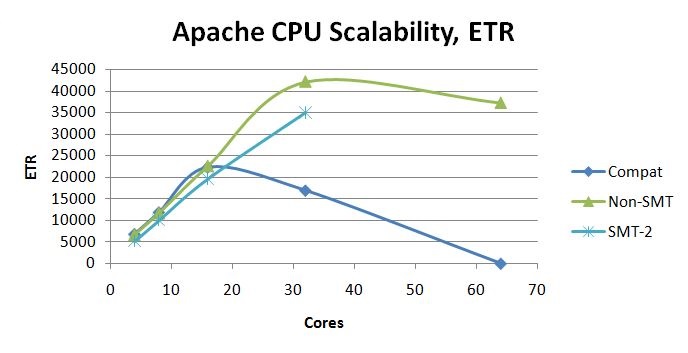
Figure 4 illustrates the ETR scaling achieved in the Apache CPU Scalability suite.
| Figure 4. Apache CPU Scalability ETR scaling curves. 2964-NC9, dedicated LPAR, storage-rich. z/VM 6.3 with z13 compatibility SPE. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. z/VM 6.3 with z13 exploitation SPE and VM65696, SMT-2. |
|
The ETR curve for SMT-2 tracks below the ETR curve for non-SMT. To investigate this we examined the 32-core runs. The reason for the result is that the AWM clients, which are virtual 1-ways, are completely busy and are running on logical CPUs that individually deliver less computing power than they did in the non-SMT case. See Table 8. For a discussion of mitigation techniques, see our SMT chapter.
| Table 8. Apache CPU Scalability, 32-core. | |||||
| Run ID | A32XX0T0 | A32XX0T1 | |||
| Cores | 32 | 32 | |||
| SMT configuration | non-SMT | SMT-2 | |||
| Clients | 24 | 24 | |||
| Client N-way | 1 | 1 | |||
| Client %busy each | 94.5 | 96.0 | |||
| Logical CPU avg %busy | 100 | 56 | |||
| CPU MF MIPS | 99565 | 85390 | |||
| Notes: 2964-NC9. z/VM for z13 with VM65696. | |||||
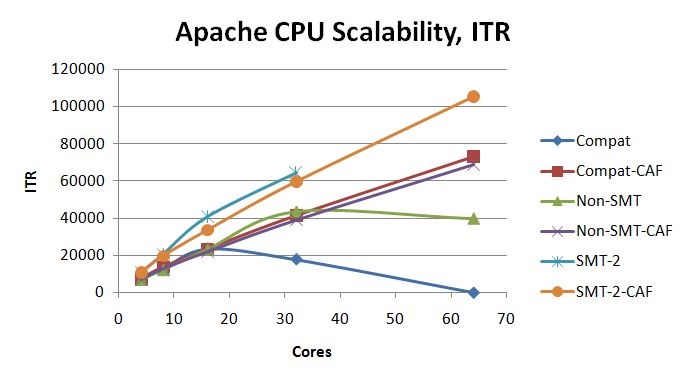
Figure 5 illustrates the ITR scaling achieved in the Apache CPU Scalability suite. The curves marked CAF are the expectation curves formed by computing how the experiment's smallest run would have scaled up according to the CAF coefficients.
| Figure 5. Apache CPU Scalability ITR scaling curves. 2964-NC9, dedicated LPAR, storage-rich. z/VM 6.3 with z13 compatibility SPE. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. z/VM 6.3 with z13 exploitation SPE and VM65696, SMT-2. |
|
For z/VM 6.3 with merely the z13 compatibility SPE, the 64-core non-SMT run failed to operate and so ETR and ITR were recorded as zero.
For z/VM for z13 in non-SMT mode, the rolloff at 64 cores is explained by the behavior of the z13 CPC when the LPAR spans two drawers of the machine. Though L1 miss percent and path length remained fairly constant across the three runs, clock cycles needed to resolve an L1 miss increased to 168 cycles in the two-drawer case. This caused CPI to rise which in turn caused processing power available to the LPAR to drop. See Table 9. Field results will vary widely according to workload.
| Table 9. Apache CPU Scalability, non-SMT. | |||||
| Run ID | A16XX0T0 | A32XX0T0 | A64XX0T0 | ||
| Cores | 16 | 32 | 64 | ||
| Drawers | 1 | 1 | 2 | ||
| Infinite CPI | 1.15 | 1.17 | 1.22 | ||
| Finite CPI | 0.28 | 0.43 | 2.21 | ||
| Total CPI | 1.43 | 1.60 | 3.43 | ||
| L1 miss percent | 1.31 | 1.37 | 1.32 | ||
| Sourcing cycles per L1 miss | 21.02 | 30.78 | 168.21 | ||
| M inst per transaction | 2.418 | 2.376 | 2.555 | ||
| Notes: 2964-NC9. Dedicated LPARs, storage-rich. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. | |||||
Apache DASD Paging
Table 10 illustrates basic results from the Apache DASD Paging suite, using z/VM 6.3 with the z13 compatibility SPE.
| Table 10. Apache DASD Paging Results, Compatibility | |||||
| Cores | 4 | 8 | 16 | 32 | 64 |
| Run ID | A04DPUX0 | A08XDPU0 | A16DPUX0 | A32DPUX0 | A64DPUX0 |
| ETR | 319 | 315 | 327 | 262 | 121 |
| ITR | 352 | 583 | 827 | 289 | 222 |
| Avg logical PU %busy | 91 | 54 | 40 | 91 | 54 |
| T/V ratio | 1.59 | 1.92 | 2.87 | 18.28 | 34.9 |
| Notes: 2964-NC9; z/VM 6.3 with VM65577. | |||||
Table 11 illustrates basic results from the Apache DASD Paging suite, using z/VM for z13, non-SMT mode.
| Table 11. Apache DASD Paging Results, non-SMT | |||||
| Cores | 4 | 8 | 16 | 32 | 64 |
| Run ID | A04DX0T0 | A08DX0T0 | A16DX0T0 | A32DX0T0 | A64DX0T1 |
| ETR | 315 | 333 | 371 | 386 | 366 |
| ITR | 347 | 613 | 1190 | 1982 | 2499 |
| Avg logical PU %busy | 91 | 54 | 31 | 19 | 15 |
| T/V ratio | 1.56 | 1.79 | 1.99 | 2.74 | 3.22 |
| Notes: 2964-NC9; z/VM for z13 with VM65696. | |||||
Table 12 illustrates basic results from the Apache DASD Paging suite, using z/VM for z13, SMT-2 mode.
| Table 12. Apache DASD Paging Results, SMT-2 | ||||
| Cores | 4 | 8 | 16 | 32 |
| Run ID | A04DX0T2 | A08DX0T1 | A16DX0T1 | A32DX0T1 |
| ETR | 317 | 334 | 398 | 416 |
| ITR | 492 | 1017 | 2272 | 3954 |
| Avg logical PU %busy | 64 | 33 | 18 | 11 |
| T/V ratio | 1.65 | 1.84 | 1.95 | 2.46 |
| Notes: 2964-NC9; z/VM for z13 with VM65696. | ||||
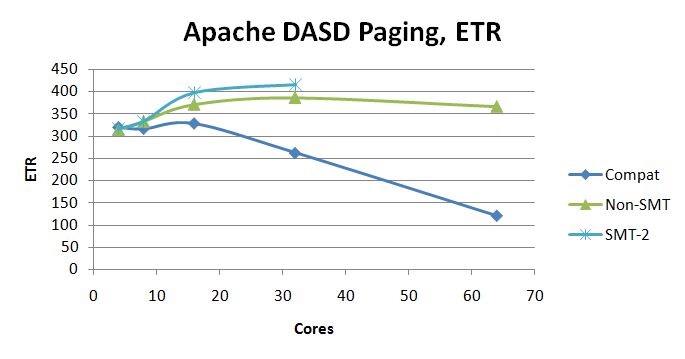
Figure 6 illustrates the ETR scaling achieved in the Apache DASD Paging suite.
| Figure 6. Apache DASD Paging ETR scaling curves. 2964-NC9, dedicated LPAR, storage-constrained. z/VM 6.3 with z13 compatibility SPE. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. z/VM 6.3 with z13 exploitation SPE and VM65696, SMT-2. |
|
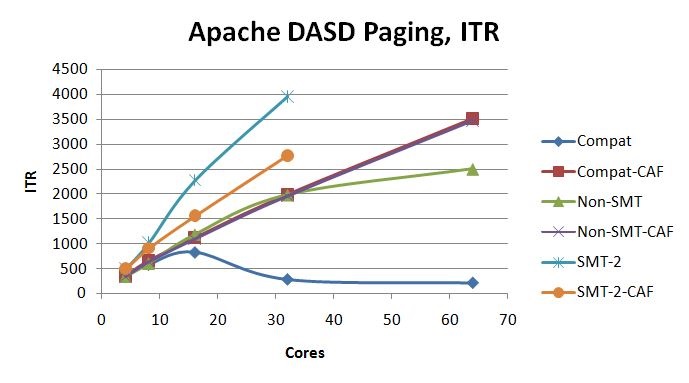
Figure 7 illustrates the ITR scaling achieved in the Apache DASD Paging suite. The curves marked CAF are the expectation curves formed by computing how the experiment's smallest run would have scaled up according to the CAF coefficients.
| Figure 7. Apache DASD Paging ITR scaling curves. 2964-NC9, dedicated LPAR, storage-constrained. z/VM 6.3 with z13 compatibility SPE. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. z/VM 6.3 with z13 exploitation SPE and VM65696, SMT-2. |
|
For z/VM for z13 in non-SMT mode, the rolloff at 64 cores is due to a number of factors. Compared to the 32-core run, CPI is increased 7% and path length is increased 26%. As illustrated by Table 13, the growth in CPU time per transaction is in the z/VM Control Program. Areas of interest include CPU power spent spinning on the HCPPGDAL lock and CPU power spent spinning on the SRMATDLK lock.
| Table 13. Apache DASD Paging, non-SMT. | |||||
| Run ID | A16DX0T0 | A32DX0T0 | A64DX0T1 | ||
| Cores | 16 | 32 | 64 | ||
| Drawers | 1 | 1 | 2 | ||
| Infinite CPI | 1.17 | 1.09 | 1.07 | ||
| Finite CPI | 1.56 | 1.96 | 2.20 | ||
| Total CPI | 2.73 | 3.05 | 3.27 | ||
| L1 miss percent | 5.37 | 4.57 | 4.28 | ||
| Sourcing cycles per L1 miss | 28.95 | 43.11 | 52.87 | ||
| M inst per transaction | 22.3 | 26.0 | 32.9 | ||
| SIEs per second | 768591 | 728909 | 739401 | ||
| Guest busy/tx (p) | 0.6748 | 0.5887 | 0.6291 | ||
| Chargeable CP busy/tx (p) | 0.4208 | 0.5835 | 0.6663 | ||
| Nonchargeable CP busy/tx (p) | 0.2494 | 0.4423 | 0.7299 | ||
| T/V ratio | 1.99 | 2.74 | 3.22 | ||
| SRMSLOCK coll/sec | 1107 | 2087 | 2723 | ||
| SRMSLOCK usec/coll | 2.3 | 11.9 | 33.3 | ||
| SRMSLOCK spin %busy | 0.26 | 2.48 | 9.07 | ||
| HCPPGDAL coll/sec | 18858 | 17848 | 19225 | ||
| HCPPGDAL usec/col | 4.82 | 7.01 | 9.71 | ||
| HCPPGDAL spin %busy | 9.1 | 12.5 | 18.67 | ||
| SRMATDLK coll/sec | 1791 | 3680 | 5534 | ||
| SRMATDLK usec/coll | 15.1 | 29.8 | 43.2 | ||
| SRMATDLK spin %busy | 2.7 | 11.0 | 23.9 | ||
| Notes: 2964-NC9. Dedicated LPARs, storage-constrained. z/VM 6.3 with z13 exploitation SPE and VM65696, non-SMT. | |||||
Microbenchmark: Guest PTE Serialization
Table 14 shows the result of the guest PTE serialization experiment. CPU time spent spinning in PTE serialization was decreased from 37 engines' worth to 4.5 engines' worth.
| Table 14. Guest PTE Serialization Result | |||||
| Run ID | L9XB110 | L9392200 | |||
| %Busy spinning in locking PTEs | 3700 | 450 | |||
| Notes: zEC12 2827-795. Dedicated LPAR with 39 logical CPUs. LPAR is storage-rich. Linux guest is 39 virtual CPUs and storage-rich. Linux SLES 11 SP 3 with memtst application. Base case is z/VM 6.3 as of August 6, 2013. Comparison case is z/VM 6.3 internal driver of February 20, 2014 with PTE serialization fix applied. | |||||
The PTE serialization improvement met expectation.
Microbenchmark: VDISK Serialization
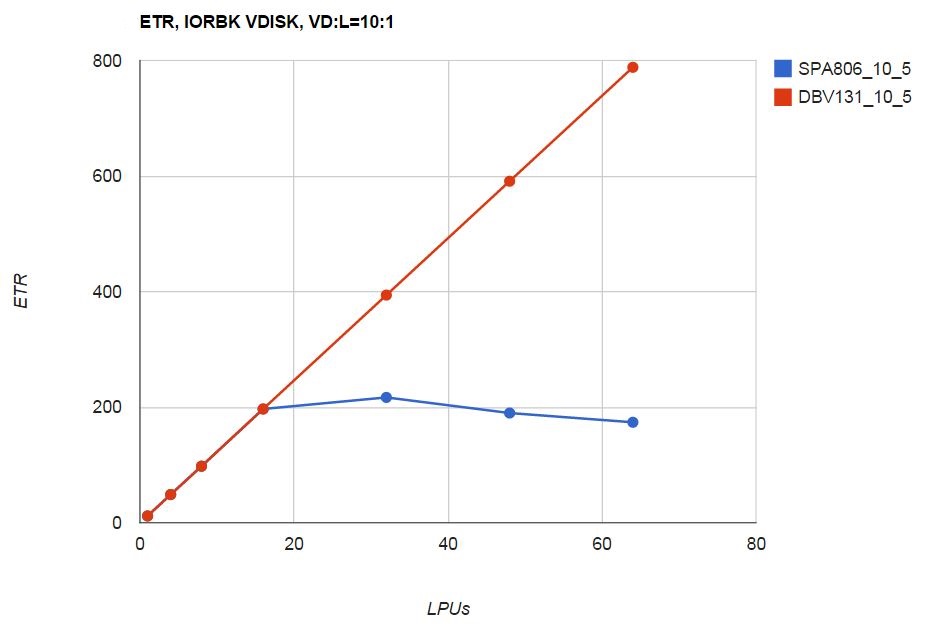
Figure 8 shows the VDISK workload's ETR as a function of number of cores.
| Figure 8. VDISK scaling workload ETR. zEC12, storage-rich dedicated LPAR. z/VM 6.3 unmodified (SPA806_10_5). z/VM 6.3 including VDISK serialization improvement (DBV131_10_5). NB: LPUs means logical CPUs in the LPAR. |
|
Figure 9 shows the VDISK workload's ITR as a function of number of cores.
| Figure 9. VDISK scaling workload ITR. zEC12, storage-rich dedicated LPAR. z/VM 6.3 unmodified (SPA806_10_5). z/VM 6.3 including VDISK serialization improvement (DBV131_10_5). NB: LPUs means logical CPUs in the LPAR. |
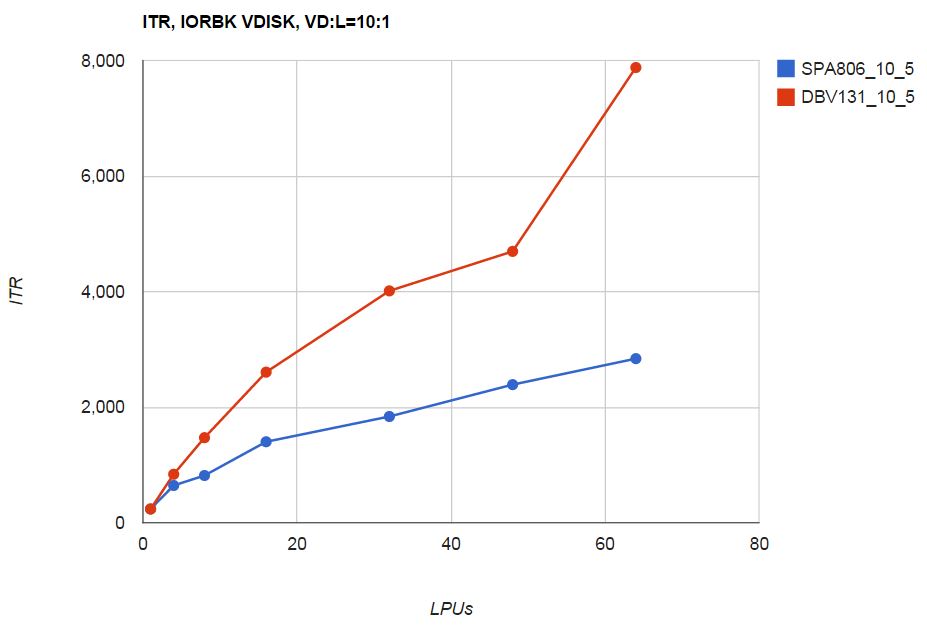
|
The VDISK serialization improvement met expectation.
Microbenchmark: Real Storage Management Serialization
Figure 10 shows the spin lock characteristics of the 30-way version of the workload. The comparison run shows all spin time on the real storage lock RSA2GLCK was removed.
| Figure 10. 30-way guest page instantiation workload. zEC12, storage-rich dedicated LPAR. z/VM 6.3 unmodified (X0SPA806). z/VM 6.3 improved (X0DBC507). |
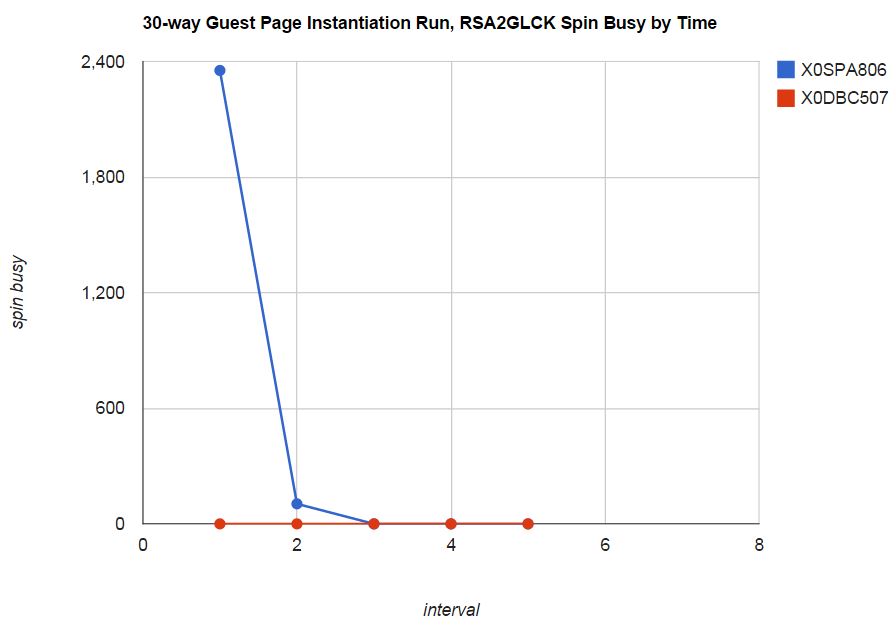
|
Figure 11 shows the spin lock characteristics of the 60-way version of the workload. Though some RSA2GLCK spin remains in the comparison run, the period of contention is shortened from four intervals to two intervals and spin busy on RSA2GLCK is reduced from 5542% to 2967%, for a savings of 25.75 engines' worth of CPU power.
| Figure 11. 60-way guest page instantiation workload. zEC12, storage-rich dedicated LPAR. z/VM 6.3 unmodified (X0SPA806). z/VM 6.3 improved (X0DBC507). |
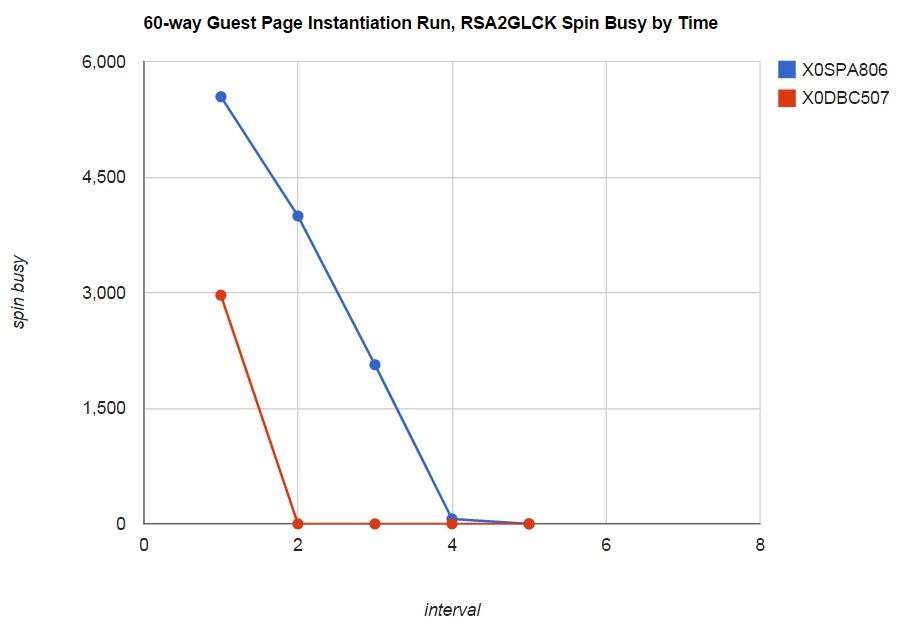
|
The real storage management improvement met expectation.
Summary and Conclusions
With z/VM for z13 IBM increased the support limit for logical CPUs in an LPAR. On a z13 the support limit is 64 logical CPUs. On other machines the support limit remains at 32 logical CPUs.
Measurements of DayTrader, a middleware-rich workload, showed correct scaling up to 64 logical CPUs, whether running in non-SMT mode or in SMT-2 mode. Measurements of certain middleware-light, z/VM Control Program-rich workloads achieved correct scaling on up to 32 cores, whether running in non-SMT mode or in SMT-2 mode. Beyond 32 cores, the z/VM CP-rich workloads exhibited some rolloff.
In developing z/VM for z13 IBM discovered three specific areas of
the z/VM Control Program where focused work on constraint relief
was warranted. These areas were
PTE serialization,
VDISK I/O, and
real storage management.
The z/VM for z13 PTF contains improvements for those three areas.
In highly focused microbenchmarks the improvements met
expectation.