Vswitch Priority Queueing
Abstract
New function Vswitch Priority Queueing provides a means to direct a virtual NIC's (VNIC's) outbound packets to a low-priority, normal-priority, or high-priority output queue on a vswitch's uplink port. In this way, different VNICs can be provided with different grades of uplink service.
Compared to not having the PTFs installed, using a vswitch with the PTFs installed provided CPU efficiency (ITR) benefit, even with the priority queueing function itself not exploited. When priority queueing was enabled and the OSA was fully saturated, the outbound data rate of a guest was reflective of the queue used by the guest. When the OSA was lightly used, guests running the same workload experienced a similar outbound data rate, regardless of the queue they used. The internal transaction rate (ITR) of all workloads saw an increase of 4.3% to 36.3% when the PTFs were installed.
PTFs UM35465 for APAR VM66219, UI62768 for APAR PH04703, and UV99352 for APAR VM66223 implement the new function.
Customer results will vary according to system configuration and workload.
Background
Vswitch Priority Queueing exploits the priority queueing capabilities of the OSA-Express adapter. Prior to the new support, z/VM used a single uplink queue when delivering outbound data to an OSA-Express adapter. Outbound vswitch data transmission occurred in a first-in, first-out (FIFO) manner. When the new support is enabled, the z/VM vswitch establishes four output queues for the transmission of outbound data, changing the transmission of outbound data from a FIFO scheme to a four-level priority scheme, FIFO within priority level. A single inbound queue continues to be used for inbound data.
The four output queues are weighted. The queue with the highest weight is reserved for internal use by z/VM. This queue is used for vswitch management communications. The system administrator can exploit the remaining three queues to prioritize the uplink transmission of data originating from VNICs connected to the vswitch. These queues are referred to as the high, normal, and low queues. Their names reflect their relative weights.
The OSA-Express adapter services the four outbound queues in a round-robin manner. The maximum number of buffers processed per visit to a given queue is capped and varies by queue.
The priority queueing function is most relevant when the OSA-Express device approaches full saturation. The less saturated the OSA-Express device is, the less the queue priority matters.
Method
The new support was evaluated using streaming workloads and request/response workloads. Figure 1 illustrates the environment.
| Figure 1. Priority queueing workload environment. |
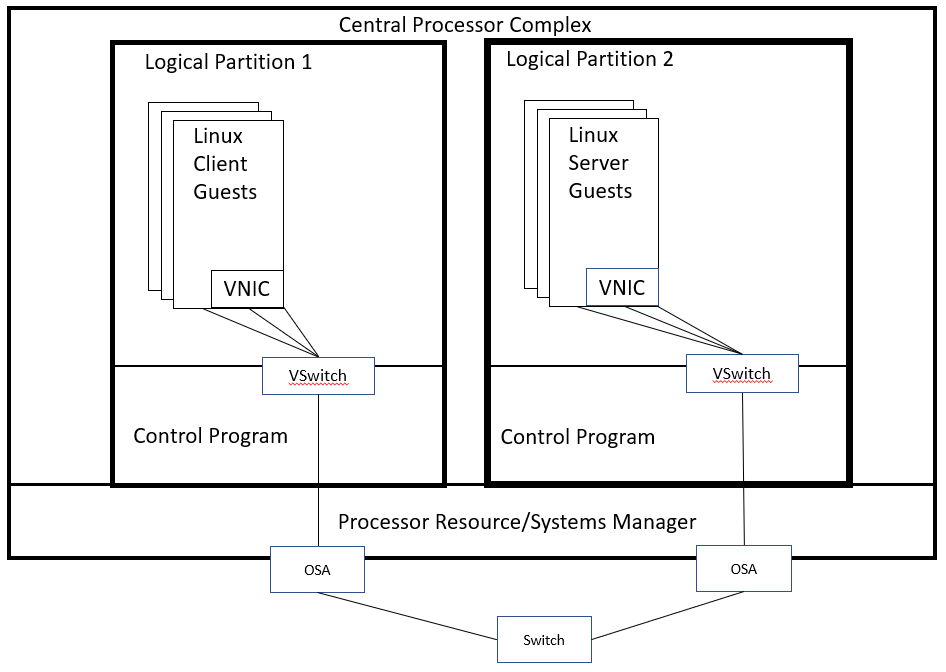
|
| Notes: CPC type 3906-M05, 512 GB central storage, four or eight dedicated IFL cores, OSA-Express 5S, and z/VM 7.1 with or without the priority queueing PTFs. |
All experiments were run on an IBM 3906 z14 Model M05 and used two similarly configured logical partitions. Two sets of experiments were conducted with both partitions configured with 512 GB central storage and eight dedicated IFL cores. One set of experiments was conducted with both partitions configured with 512 GB central storage and four dedicated IFL cores. While the measurements were taken, no other partitions were activated. All experiments were performed using SMT-1 mode.
Experiments used a streaming workload (STR), a request/response workload (RR), or a combination of STR and RR workloads. The streaming workload consisted of clients sending 20-byte requests and the server sending 20-megabyte responses. The request/response workload consisted of clients sending 200-byte requests and the server sending 2000-byte responses. Linux guests on one partition functioned as clients while Linux guests on the other partition functioned as servers. Clients and servers were paired such that a single client managed multiple connections to a single server.
Vswitches were used to connect the clients and servers. The vswitches were defined to use an OSA-Express 5S adapter. When the vswitches were enabled for priority queueing, a client guest and its corresponding server guest were configured with the same priorities.
An MTU size of 8992 bytes was used for all workloads.
Results and Discussion
Streaming Workload
Our first measurements evaluated the effect of priority queueing on a streaming workload. The first measurement collected baseline data from a z/VM system not having the PTFs. The rest of the measurements collected data from runs where we increased the influence of the new support: first with the PTFs merely present on the system but not exploited, and then with the support in play but the guests prioritized equally, and then with the guests prioritized differently. Table 1 presents server-side results from a streaming workload.
| Table 1. Streaming measurements. | ||||
| Run ID | STR-BASE | STR-OFF | STR-NNN | STR-LNH |
| Priority queueing PTFs installed | No | Yes | Yes | Yes |
| Priority queueing enabled | - | No | Yes | Yes |
| Guests prioritized differently | - | - | No | Yes |
| ETR | 56.1 | 56.1 | 56.1 | 56.0 |
| ITR | 389.6 | 431.6 | 431.2 | 454.6 |
| Delta in ETR from STR-BASE | - | 0% | 0% | -0.2% |
| Delta in ITR from STR-BASE | - | 10.8% | 10.7% | 16.7% |
| LNS00001 Priority | - | N/A | Normal | Low |
| LNS00001 %CPU | 30.6 | 28.0 | 27.8 | 18.6 |
| LNS00001 Outbound Xmit pkts/sec | 43,806 | 44,304 | 43,779 | 31,166 |
| LNS00002 Priority | - | - | Normal | Normal |
| LNS00002 %CPU | 31.0 | 28.0 | 28.1 | 24.6 |
| LNS00002 Outbound Xmit pkts/sec | 44,666 | 44,375 | 44,409 | 41,574 |
| LNS00003 Priority | - | - | Normal | High |
| LNS00003 %CPU | 30.5 | 27.5 | 27.7 | 34.8 |
| LNS00003 Outbound Xmit pkts/sec | 43,888 | 43,446 | 43,890 | 59,416 |
| Total Outbound Xmit pkts/sec | 132k | 132k | 132k | 132k |
Notes:
| ||||
Run STR-BASE was collected on a level of z/VM that did not have the PTFs. It is a base run to which subsequent runs will be compared.
Run STR-OFF was collected on a level of z/VM that had the PTFs, but the new support was not activated. The purpose of STR-OFF was to check for performance regression compared to STR-BASE. No regression was found, and in fact, ITR improved by 10.8%.
Run STR-NNN was collected with all VNICs coupled to the normal-priority outbound queue. We expected performance like STR-OFF. Our expectation was met.
Run STR-LNH was collected with VNICs coupled at low, normal, and high priorities. The purpose was to check whether the queue priorities influenced the data rates. Influence was observed.
The total outbound data rate of the three guests remained constant across all runs. We expected this because we designed these workloads to saturate the OSA-Express adapter.
Request/Response Workload
Our next measurements evaluated the effect of priority queueing on a request/response workload. As we did in streaming, we designed a sequence of measurements that would evaluate the influence of the new support as we increased our exploitation of it. Table 2 shows server-side measurements of a request/response workload.
| Table 2. Request/response measurements. | ||||
| Run ID | RR-BASE | RR-NNN | RR-LNH | |
| Priority queueing PTFs installed | No | Yes | Yes | |
| Priority queueing enabled | - | Yes | Yes | |
| Guests prioritized differently | - | No | Yes | |
| ETR | 63,133.7 | 67,749.3 | 67,965.8 | |
| ITR | 1,002,122.4 | 1,110,644.7 | 1,045,627.6 | |
| Delta in ETR from RR-BASE | - | 7.3% | 7.7% | |
| Delta in ITR from RR-BASE | - | 10.8% | 4.3% | |
| LNS00001 Priority | - | Normal | Low | |
| LNS00001 %CPU | 13.1 | 13.7 | 13.6 | |
| LNS00001 Outbound Xmit pkts/sec | 20,369 | 21,871 | 21,936 | |
| LNS00002 Priority | - | Normal | Normal | |
| LNS00002 %CPU | 13.1 | 13.7 | 13.6 | |
| LNS00002 Outbound Xmit pkts/sec | 20,369 | 21,873 | 21,936 | |
| LNS00003 Priority | - | Normal | High | |
| LNS00003 %CPU | 13.0 | 13.6 | 13.6 | |
| LNS00003 Outbound Xmit pkts/sec | 20,369 | 21,873 | 21,936 | |
| Total Outbound Xmit pkts/sec | 61,028 | 65,531 | 65,740 | |
Notes:
| ||||
Run RR-BASE was collected on a level of z/VM that did not have the PTFs. It is a base run to which subsequent runs will be compared.
Run RR-NNN was collected with all VNICs coupled to the normal-priority outbound queue. We expected performance at least matching RR-BASE. We observed an ETR increase of 7.3% and an ITR increase of 10.8%.
Run RR-LNH was collected with VNICs coupled at low, normal, and high priorities. Unlike run STR-LNH, run RR-LNH did not show differences in the outbound data rate among the three guests. This lack of variation is likely due to a lower utilization of the OSA-Express adapter.
Mixed Workload
Our next measurements evaluated the effect of priority queueing on a mixed workload. Absent priority queueing, it is possible for a heavy streaming workload to dominate the use of the uplink port, thereby squeezing a light request/response workload out of the picture. But if we put the light RR workload onto the high-priority output queue and put the heavy STR workload onto the low-priority output queue, we should be able to give the RR workload better service while not appreciably compromising the service given to the STR workload. Table 3 shows server-side measurements of a mixed workload.
| Table 3. Mixed-workload measurements. | ||||
| Run ID | MIX-BASE | MIX-NN | MIX-LH | |
| Priority queueing PTFs installed | No | Yes | Yes | |
| Priority queueing enabled | - | Yes | Yes | |
| Guests prioritized differently | - | No | Yes | |
| ETR for STR workload | 56.5 | 56.2 | 56.0 | |
| ITR for STR workload | 210.7 | 231.1 | 225.7 | |
| ETR for RR workload | 17,981.8 | 18,672.5 | 22,672.9 | |
| ITR for RR workload | 67,096.1 | 76,841.6 | 91,422.9 | |
| Delta in STR ETR from MIX-BASE | - | -0.5% | -0.9% | |
| Delta in STR ITR from MIX-BASE | - | 9.7% | 7.1% | |
| Delta in RR ETR from MIX-BASE | - | 3.8% | 26.1% | |
| Delta in RR ITR from MIX-BASE | - | 14.5% | 36.3% | |
| LNS00001 Priority | - | Normal | Low | |
| LNS00001 %CPU | 75.0 | 71.3 | 70.9 | |
| LNS00001 Outbound Xmit pkts/sec | 129k | 128k | 128k | |
| LNS00002 Priority | - | Normal | High | |
| LNS00002 %CPU | 12.2 | 12.0 | 13.9 | |
| LNS00002 Outbound Xmit pkts/sec | 15,505 | 15,886 | 19,649 | |
| Total Outbound Xmit pkts/sec | 144k | 144k | 147k | |
Notes:
| ||||
Run MIX-BASE was collected on a level of z/VM that did not have the PTFs. It is a base run to which subsequent runs will be compared.
Run MIX-NN was collected with all VNICs coupled to the normal-priority output queue. Each of the two workloads performed equal to or better than it did without the PTFs.
Run MIX-LH was collected with the RR workload coupled to the high-priority queue and the STR workload coupled to the low-priority queue. Compared to MIX-NN, the STR traffic behaved about the same while the RR traffic increased 21% in ETR and 19% in ITR.
Summary
Vswitch Priority Queueing provided CPU efficiency benefit in all the workloads we measured, even when its prioritization function was not exploited. When the function was exploited, on a heavily used OSA the effect of the prioritization was observed. On a lightly used OSA, the effect of the prioritization was not observed, nor would we expect it to be. We also found the prioritization function effective at keeping a heavy streaming workload from oppressing a light request-response workload.